Hi, I am Hongduan Tian, a fourth-year Ph.D. student at Trustworthy Machine Learning and Reasoning (TMLR) Group in Department of Computer Science, Hong Kong Baptist University, advised by Dr. Bo Han, and work closely with Dr. Feng Liu. Before that, I got my master degree from Nanjing University of Information Science and Technology (NUIST) and was fortunately supervised by Prof. Xiao-Tong Yuan and Prof. Qingshan Liu.
My research interests involves two aspects: (1) exploring the underlying mechanism of foundation model abilities (e.g., reasoning) and (2) improving the efficiency of foundation models. The goal of my research is to develop efficient foundation model agents based on trustworthy capabilities. Previously, I also explore test-time adaptation across various domains. Here are some representative works:
-
Trustworthy Foundation Model Agents: Exploring underlying mechanisms of agentic framework and building FM agentic frameworks.
[MAD-M$^2$] [LangPINN] -
Cross-domain Few-shot Test-time Adaptation: Achieving good generalization performance on tasks from previous data or domains.
[MOKD] [CoPA] [IFR]
We are also organizing the TMLR Young Scientist Seminars and actively seeking researchers interested in sharing their work. If you would like to give a talk, we encourage you to reach out to us.
Please feel free to email me for research, collaborations, or a casual chat.
Email: cshdtian [at] comp.hkbu.edu.hk / hongduan.tian [at] gmail.com
📣 News
- $\frak{2026.03}$: I will work as visiting student at RIKEN Imperfect Information Learning Team.
- $\frak{2026.03}$: Our paper “Lang-PINN: From Language to Physics-Informed Neural Networks via a Multi-Agent Framework” is accepted by ICLR 2026 Workshop on AI with Recursive Self-Improvement and is highlighted as Spotlight.
- $\frak{2026.01}$: Our paper “Multi-Agent Debate with Memory Masking” is accepted by ICLR 2026.
- $\frak{2025.11}$: Our paper “Cross-domain Few-shot Classification via Invariant-content Feature Reconstruction” is accepted by IJCV.
- $\frak{2024.09}$: Our paper “Mind the gap between prototypes and images in cross-domain finetuning” is accepted by NeurIPS 2024.
- $\frak{2024.05}$: Our paper “MOKD: Cross-domain finetuning for few-shot classification via maximizing optimized kernel dependence” is accepted by ICML 2024.
📖 Educations
- 2023.09 - present, Ph.D. Student, TMLR Group, Hong Kong Baptist University (HKBU), advised by Dr. Bo Han.
- 2026.03 - 2026.06, Visiting Student, RIKEN AIP, advised by Dr. Takashi Ishida and Prof. Masashi Sugiyama.
- 2018.09 – 2021.06, M.Eng, Nanjing University of Information Science and Technology (NUIST), advised by Prof. Xiao-Tong Yuan and Prof. Qingshan Liu.
- 2014.09 - 2018.06, B.Eng, Nanjing University of Information Science and Technology (NUIST).
📝 Publications
✉️ Corresponding author.
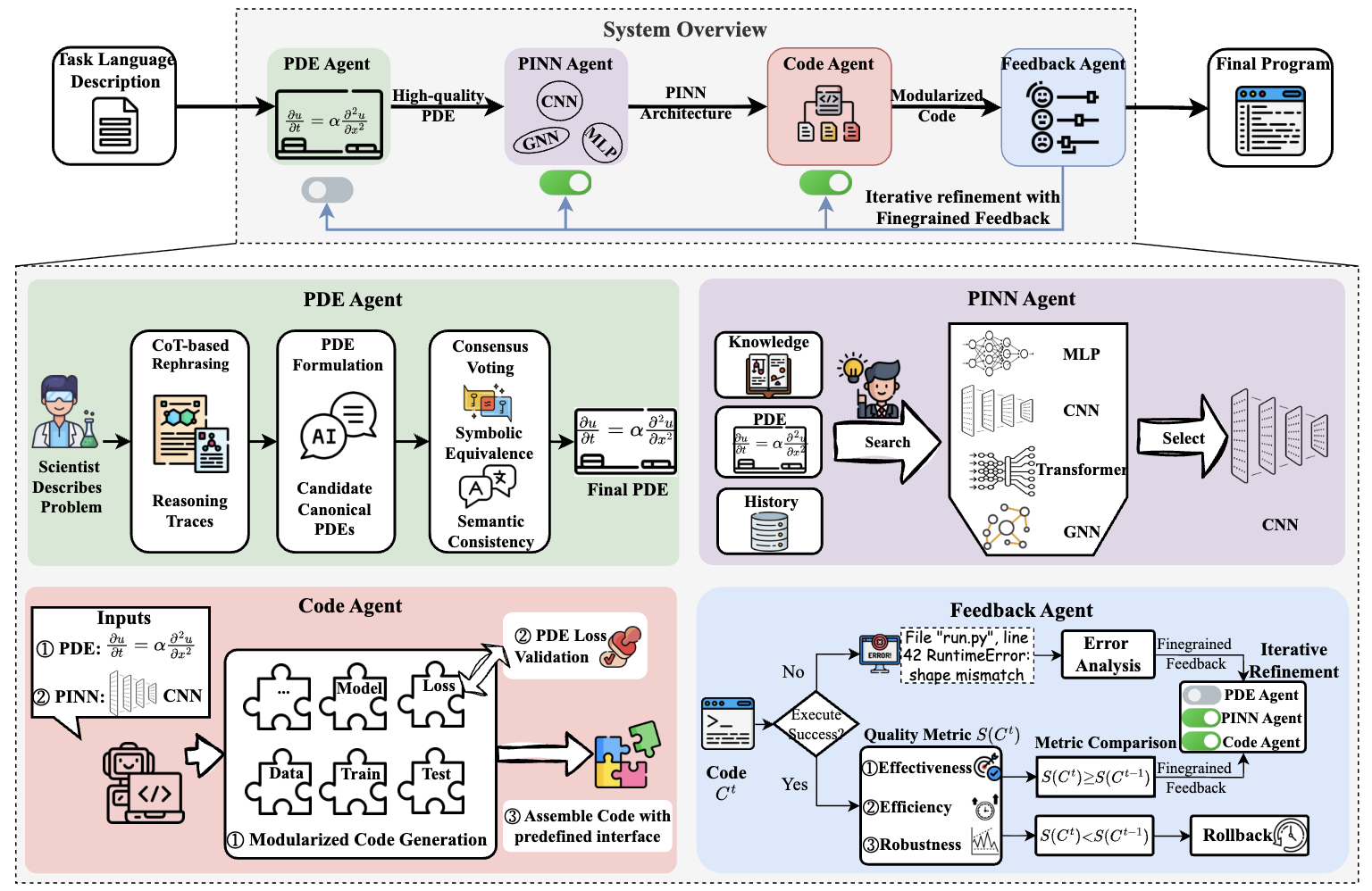
Lang-PINN: From Language to Physics-Informed Neural Networks via a Multi-Agent Framework. [Spotlight]
Xin He, Liangliang You, Hongduan Tian, Bo Han, Ivor Tsang, Yew-Soon Ong.
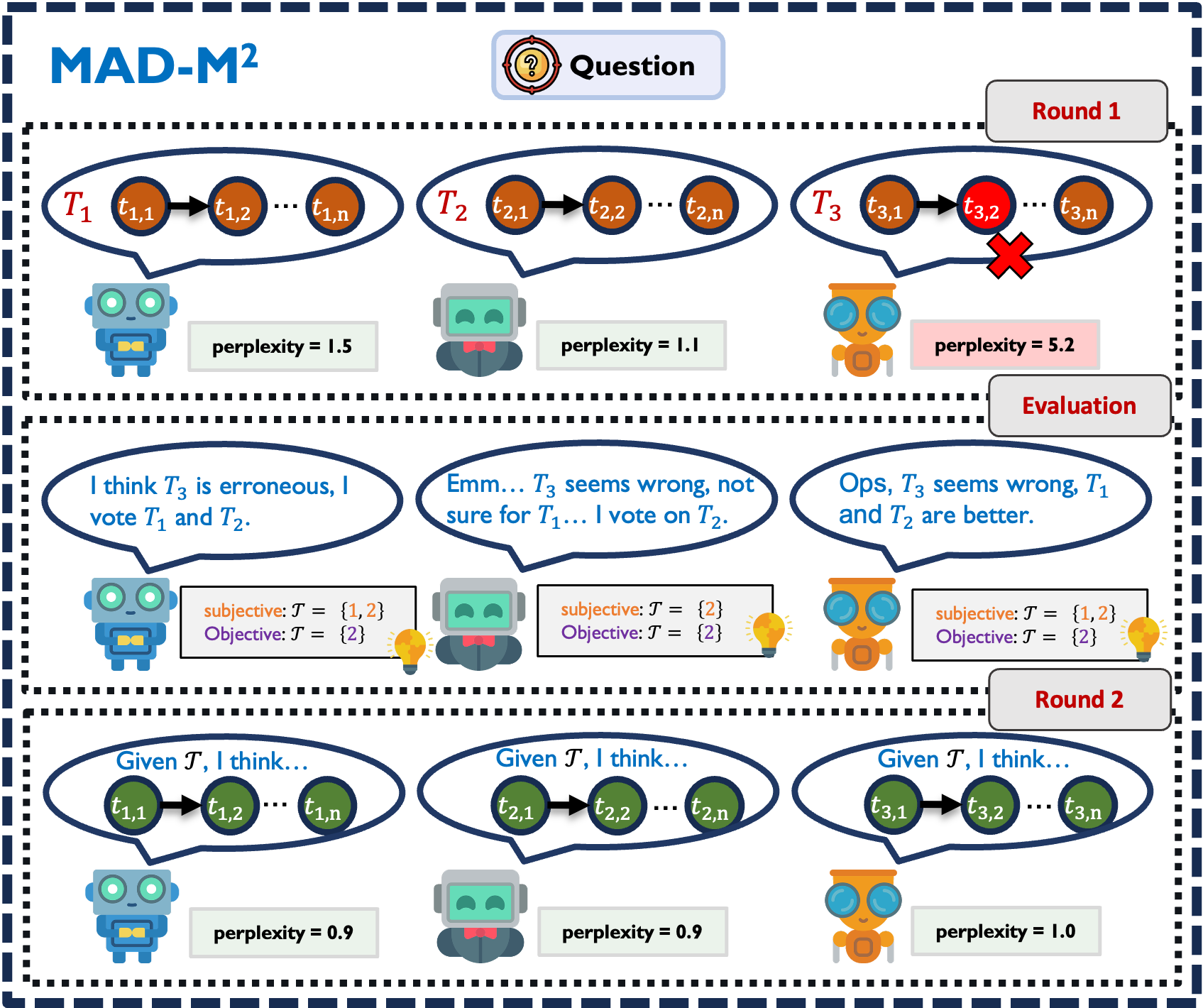
Multi-Agent Debate with Memory Masking.
Hongduan Tian, Xiao Feng, Ziyuan Zhao, Xiangyu Zhu, Rolan Yan, Bo Han✉️.
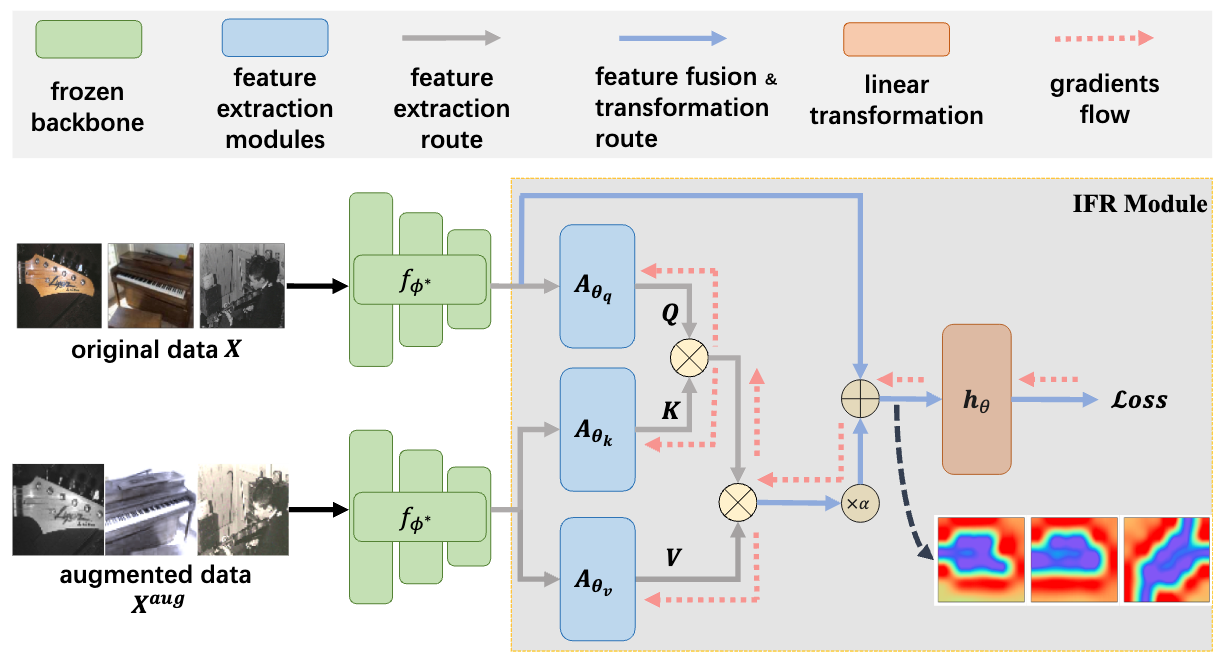

Mind the Gap Between Prototypes and Images in Cross-domain Finetuning.
Hongduan Tian, Feng Liu, Zhanke Zhou, Tongliang Liu, Chengqi Zhang, Bo Han✉️.

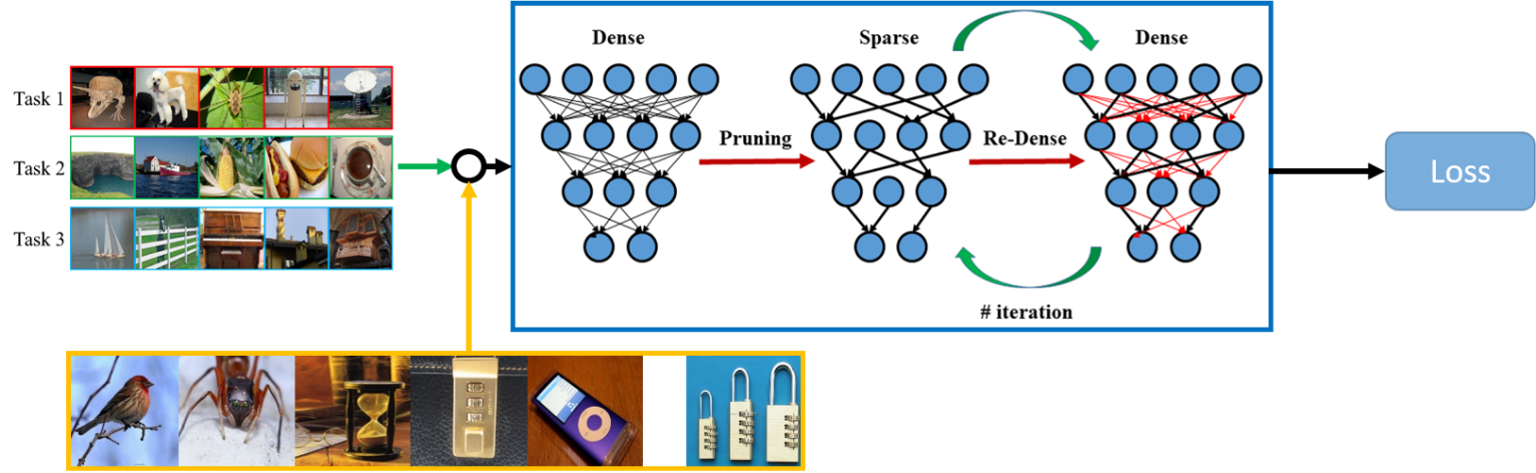
MOKD: Cross-domain Finetuning for Few-shot Classification via Maximizing Optimized Kernel Dependence.
Hongduan Tian, Feng Liu, Tongliang Liu, Bo Du, Yiu-ming Cheung, Bo Han✉️.
🎖 Awards
- 2026.06, Excellent TA Performance Award, HKBU CS Department.
- 2026.05, Research Performance Award, HKBU CS Department.
- 2026.05, Silver Reviewer Award, ICML’26.
- 2024.11, Research Performance Award, HKBU CS Department.
- 2024.10, NeurIPS Scholar Award.
🏦 Project Grants
- Research and Practice Innovation Program for Graduate Students in Jiangsu Province, SJCX20_0302, “Research on Theory and Practice of Optimization-based Meta-Learning”, 2020.04 - 2021.04
🎤 Invited Talks
- 2026.06, Towards Trustworthy Reasoning and Applicaton of Multi-agent Collaboration @Nanjing University (Suzhou), host by Prof. Xiao-Tong Yuan, Onsite.
- 2026.11, Multi-Agent Debate with Memory Masking @AI TIME, Online. [Video]
- 2024.11, Mind the Gap Between Prototypes and Images in Cross-domain Finetuning @AI TIME, Online. [Video]
- 2024.06, MOKD: Cross-domain finetuning for few-shot classification via maximizing optimized kernel dependence @AI TIME, Online. [Video]
💻 Services
- Conference Reviewer for ICML, NeurIPS, ICLR, AAAI, AISTATS.
- Journal Reviewer for TPAMI, TIP, TNNLS, TMLR, NEUNET.
🏫 Teaching
- COMP7930 (G) Big Data Analytics, Sem. 2, 2025 - 2026
- COMP7015 (G) Artificial Intelligence, Sem. 1, 2025 - 2026
- COMP7250 (G) Machine Learning, Sem. 2, 2024 - 2025
- COMP7180 (G) Quantitative Methods for Data Analytics and Artificial Intelligence, Sem. 1, 2024 - 2025
- COMP7940 (G) Cloud Computing, Sem. 2, 2023 - 2024
🏢 Experiences
- 2024.11 - 2026.04, Remote Research Intern @WeChat, supervised by Xiangyu Zhu and Rolan Yan
- 2022.07 - 2025.12, Research Intern @NVIDIA NVAITC, host by Charles Cheung.
- 2024.06 - 2024.08, Research Intern @WeChat, host by Xiangyu Zhu and Rolan Yan
- 2023.07 - 2023.08, Research Intern @Alibaba.
- 2022.07 - 2023.05, Research intern @HKBU-TMLR Group, advised by Dr. Bo Han and Dr. Feng Liu.
- 2021.07 - 2022.07, Algorithm Engineer @ZTE Nanjing Research and Development Center.
